This article builds on the work carried out at the university of Surrey with my colleagues Pr. D. Lloyd and Dr N. Santitissadeekorn about ensemble filters for temporal point processes. The following pytorch implementation of the Ensemble Poisson Gamma Filter (EnPGF), conf. [1],[2], provides unprecedented computational capabilities. The potential of this new torch-EnPGF is illustrated with an online training simulation framework using apache kafka.
Content
Temporal point processes
Ensemble Poisson-Gamma Filter
Pytorch implementation
EnPGF Network Explorer
Apache kafka online training framework
Source code
References
Temporal point processes
Temporal point processes provide a robust mathematical framework to investigate asynchronous event sequences that arise in many real-world applications. A non exhaustive list of relevant areas of application includes earthquake modelling, communication network analysis, neurons activity, epidemic outbreak, market stock price changes ... Formally, given a history \( \mathcal{H}_t := \lbrace (i',t') | t' < t, i' \in \mathcal{I} \rbrace \) for a set of event types \(\mathcal{I}\), a multivariate temporal point process is determined by the intensity function \(\Lambda := \lbrace \lambda^i\rbrace_{i\in\mathcal{I}} \) where $$ \lambda^i(t) = \lim_{dt\rightarrow 0} \frac{P(\text{event i occurs in }[t,t+dt) | \mathcal{H}_t)}{dt}. $$ Here we consider a discrete multivariate Hawkes process where the intensity function at time \(t_{k+1}\) is defined by $$ \lambda^i_{k+1}=\mu^i+(\lambda^i_k-\mu^i)(1-\beta^i\delta t) +\sum_{j\in \mathcal{I}}\alpha^{ij}d N^j_k, $$ for a baseline intensity \(\mu^i>0\), decay rate \(\beta^i>0\) and excitation matrix \( \alpha^{ij}\), \(i,j \in \mathcal{I}\), and counting process \(N^j_n:=N^j(t_k):= \#\mathcal{H}^j_{t_k}\) .
Given the history \(\mathcal{H}\) our aim is to learn the model parameters \(\lbrace \mu^i,\beta^i,\alpha^{ij} \rbrace_{i,j \in \mathcal{I}}\) .
Ensemble Poisson-Gamma Filter
For a complete account of EnPGF please refer to Santitissadeekorn et al. [1],[2]. In a nutshell, just like any other EnKF-like filter, EnPGF consists of three main stages:Pytorch Implementation
From the start we clearly indentified EnPGf as a good condidate for large problems for offline (full time window) training, and very large problems for online (sequential) training. Although we implemented many python parallel versions of EnPGF, using various libraries such as numba, ray, pyopencl, multiprocessing,... and deployed them on Surrey HPC facilities, and despite some conforting results as compared to other existing methods, up until now we couldn't really unleash EnPGF full potential. Well, thanks to a brand new GPU and a deep detour into deep learning and the magic of pytorch and so on, we finally obtained a couple of order of magnitude gain in computational time and memory use, allowing for much bigger simulations...
import numpy as np
import torch
from torch import matmul
from tqdm import tqdm
class EnPGF():
def __init__(self,n,nens,dN,dt,device='cpu',inflation=1):
rdn1,rdn2,rdn3 = init_random_sets(seed=42)
self.device = device
self.n =torch.tensor(n).to(device)
self.nens = torch.tensor(nens).to(device)
self.lb = torch.from_numpy(rnd1.copy()).to(device)
self.mu = torch.from_numpy(np.log(rnd1.copy())).to(device)
self.beta = torch.from_numpy(np.log(rnd2.copy())).to(device)
self.alpha = torch.from_numpy(np.log(rnd3.copy())).to(device)
self.dN = torch.tensor(dN).to(device)
...
def train(self,nstep=None,reset=False):
if nstep is None:
nstep = len(self.dN)
with torch.cuda.amp.autocast():
with torch.no_grad():
for i in tqdm(range(nstep)):
kk,A = self.__analysis(self.dN[i,:])
self.__update_mu(kk,A)
self.__update_beta(kk,A)
self.__update_alpha(kk,A)
self.__forecast(self.dN[i,:])
if reset and i%500==0:
self.reset()
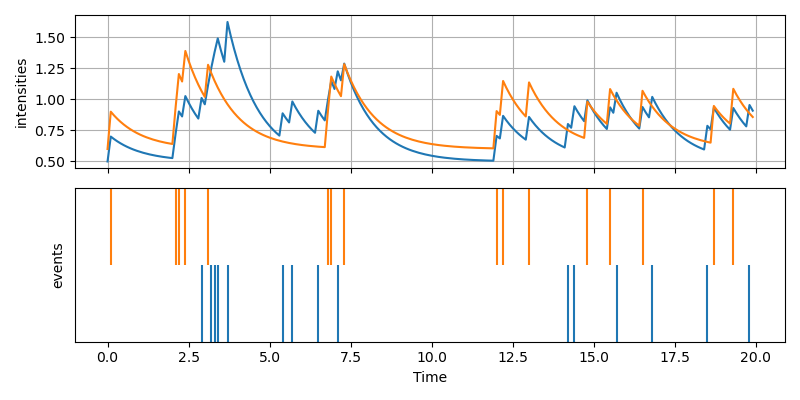
As an example, the picture below shows the true and trained excitation matrices for a simulation with \(n=128\) nodes, \(nens=128\) ensemble members, for \(10^5\) training steps.
dN,n,nstep = dN_load('dN_100000_128.csv.gzip')
enpgf= EnPGF(n=n,nens=128,dN=dN,dt=0.1,device='cuda')
enpgf.train()
enpgf.display_alpha(truth="synth_data/alphat_128_b.csv")

The run performed on a RTX 3080 takes a little more than 2 minutes to complete, that is more or less 15 times faster than our previous results. The implementation merits further improvements to allow for a more efficient memory use.
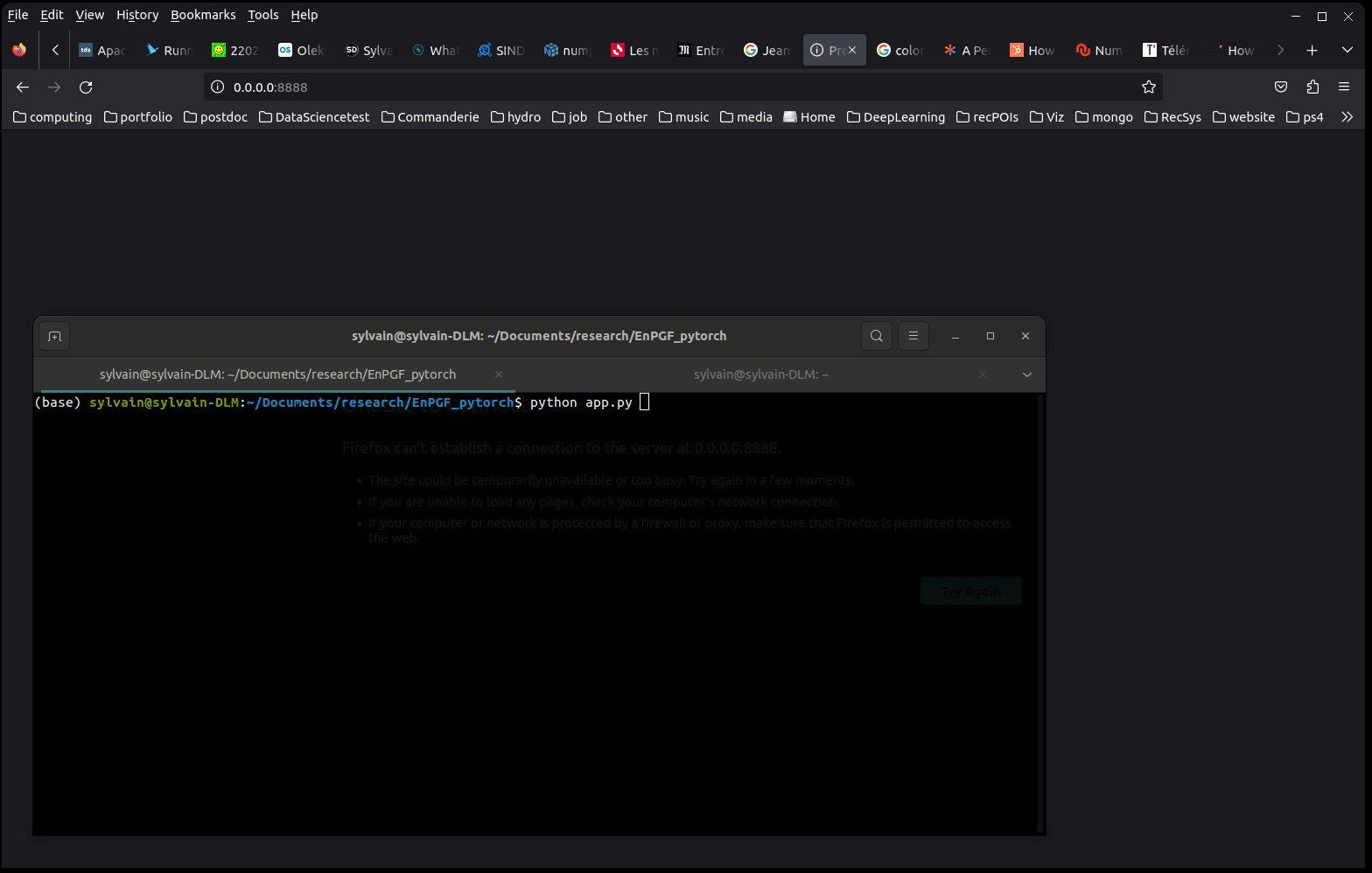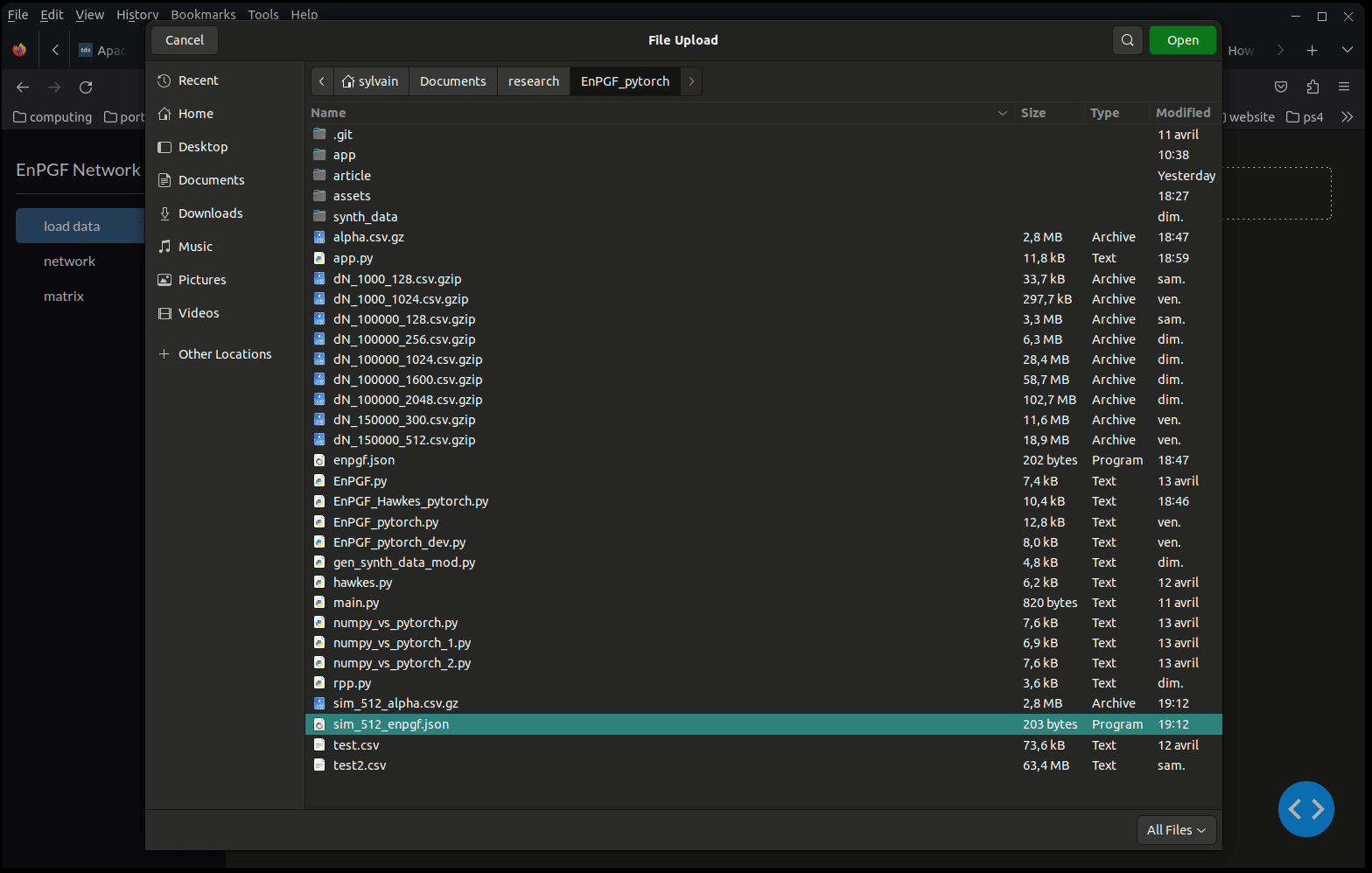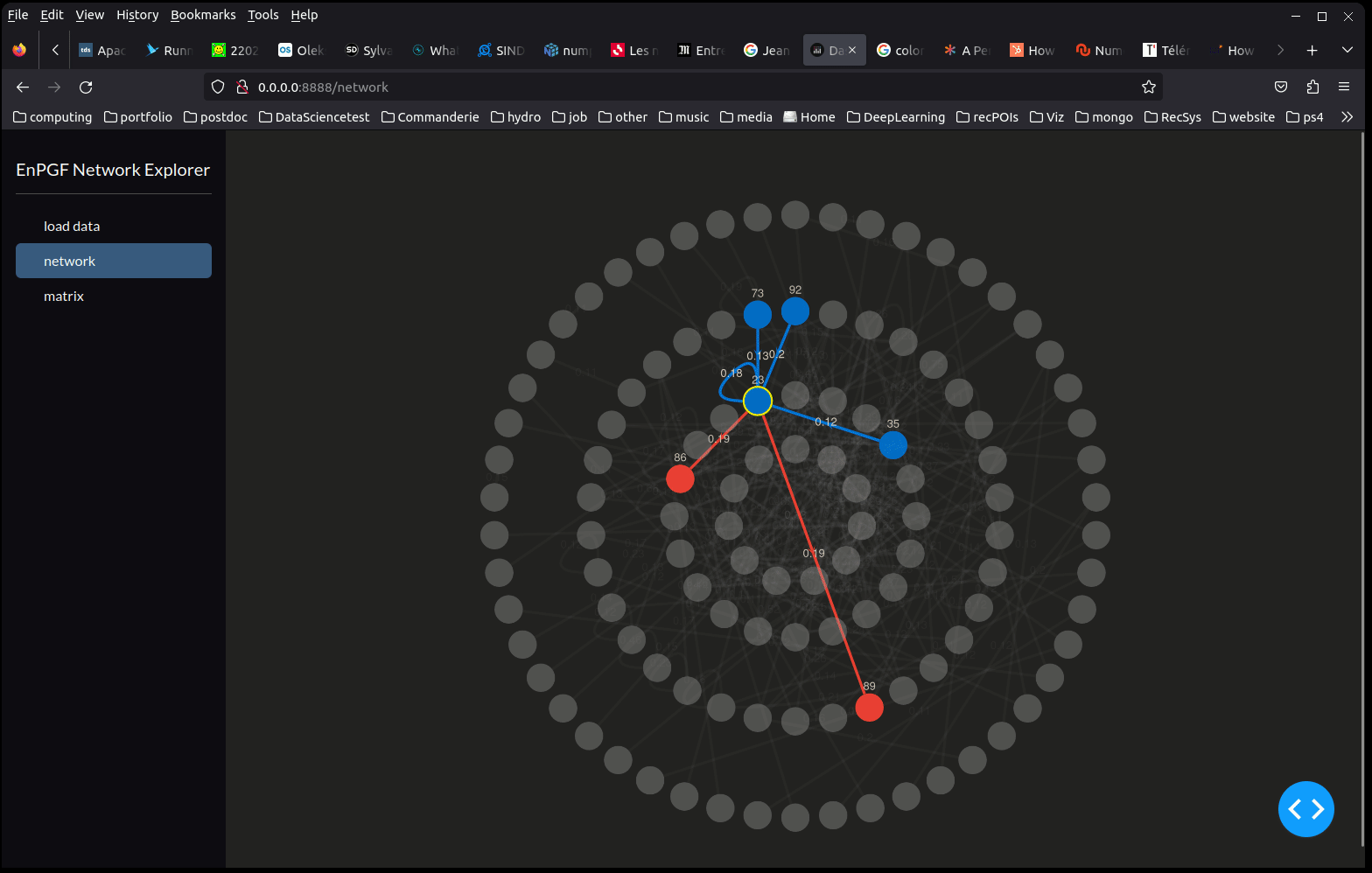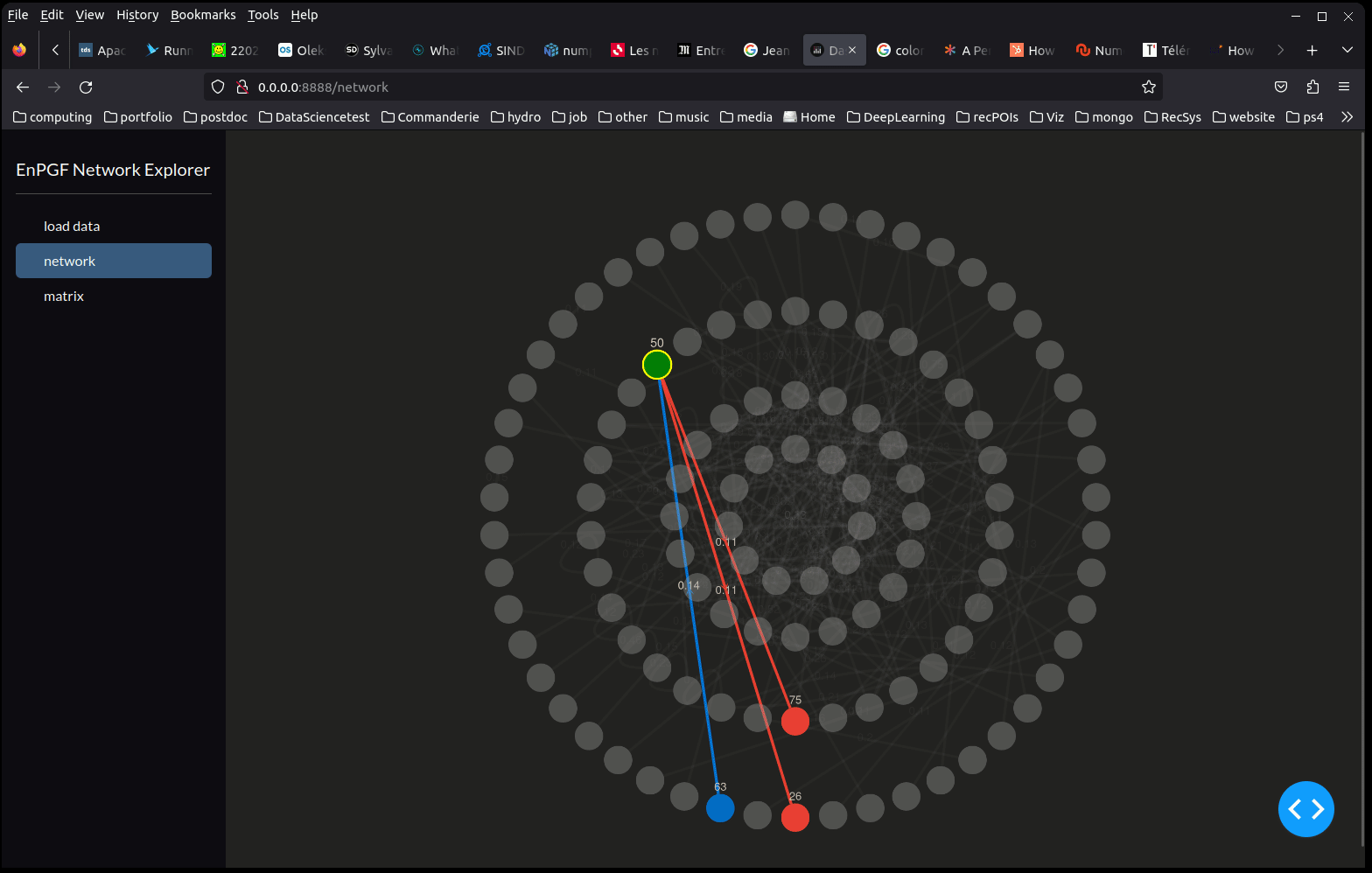
EnPGF Network explorer
Understanding the network structure of the problem at hand can become quite difficult as the number of nodes increases. To provide better insights into the infuence/excitation relationship (ref [1]) between nodes we implemented a dash-cytoscape dashboard app. The app takes the output of an EnPGF training and uses dash-cytoscape to enlight us with meaningful influential structures.
Apache kafka online training framework
The example presented above is yet relatively small and although larger simulation could be performed to demonstrate the training capabilities of EnPGF, we prefer teasing one advantage of EnPGF over other methods, namely, its sequential nature. While most other methods learn from a whole history at once, EnPGF can handle new events as they happen allowing for online training with streamed data.
To illustrate this feature of EnPGF we propose the following online training simulation framework using apache kafka. We define:
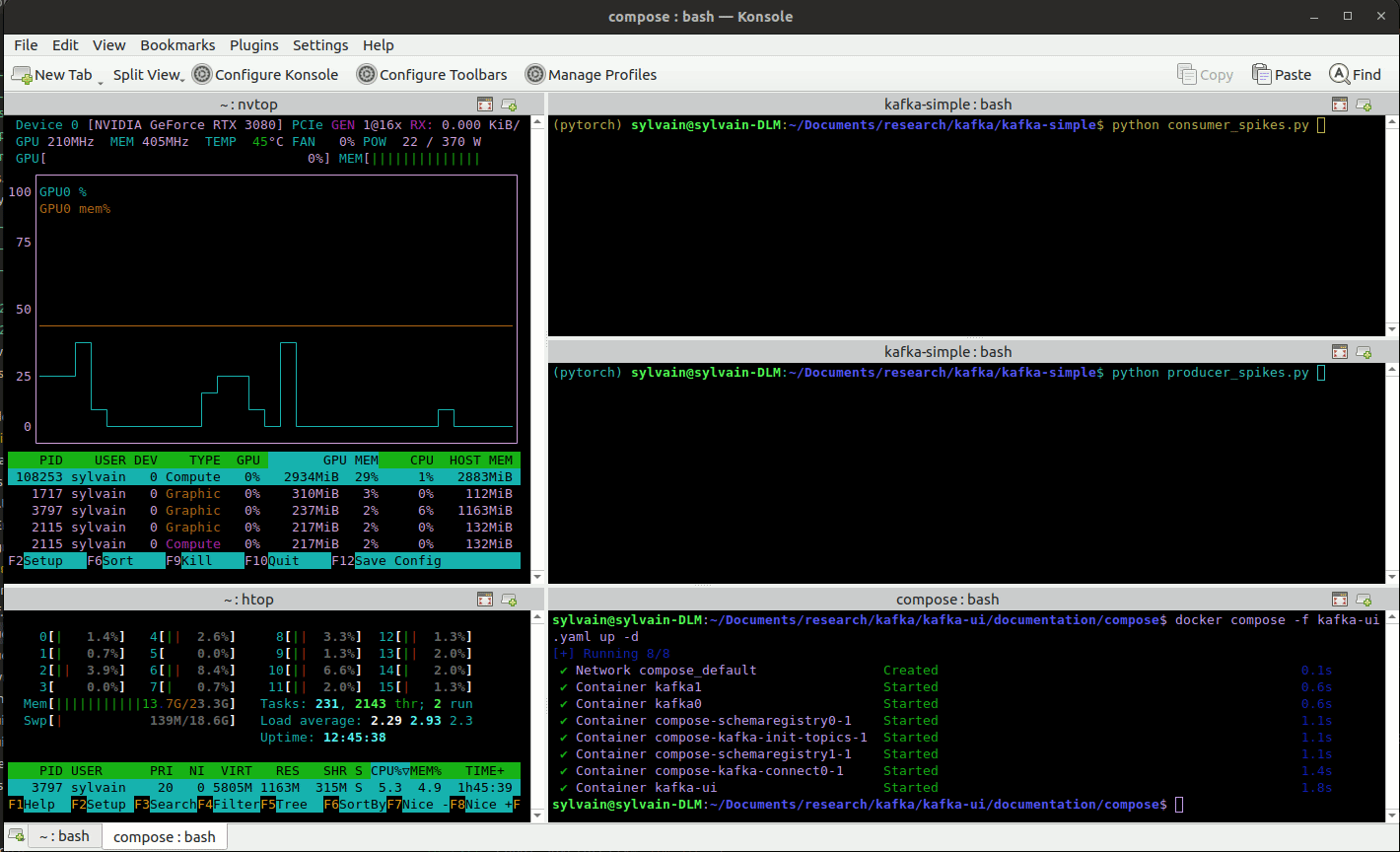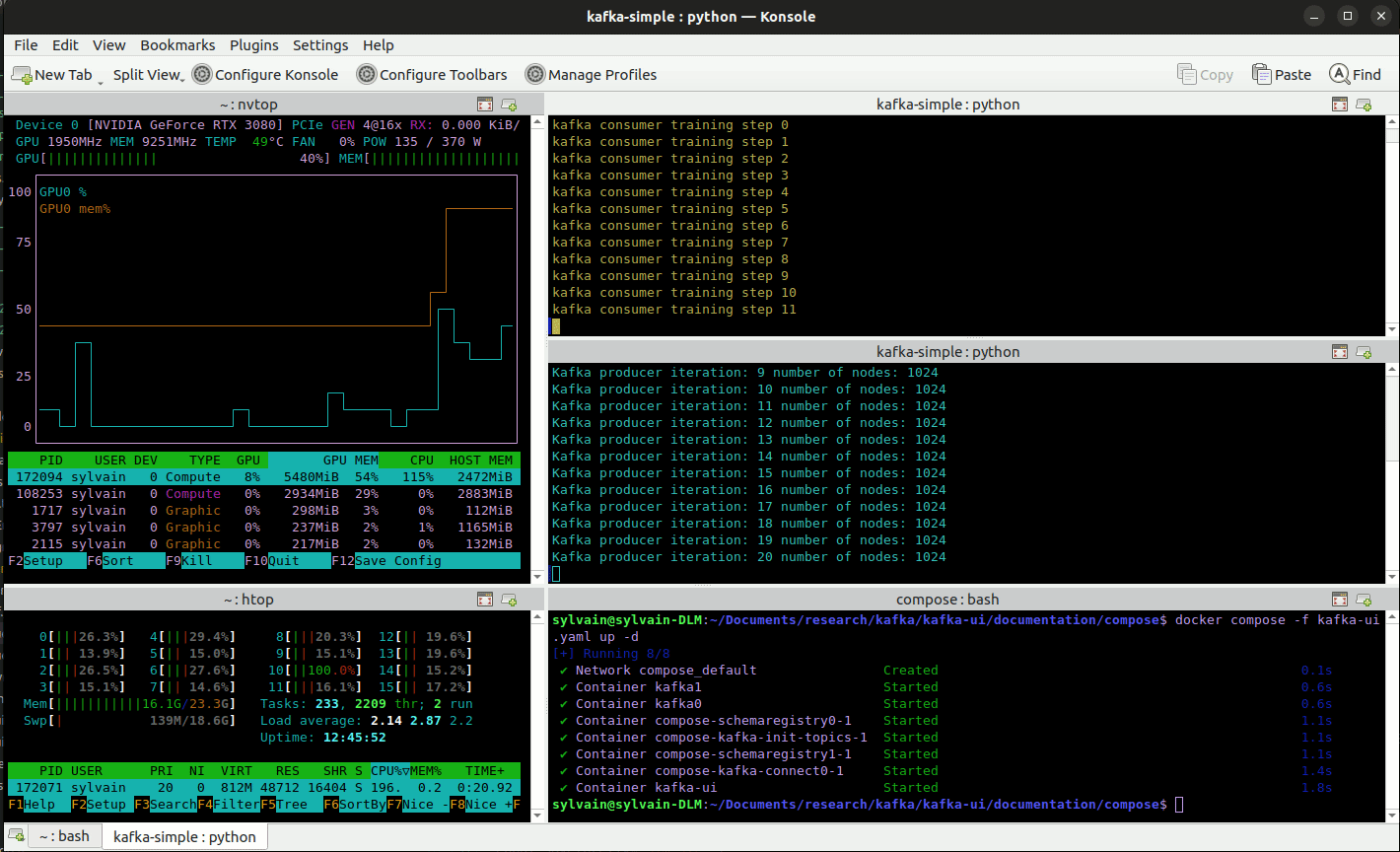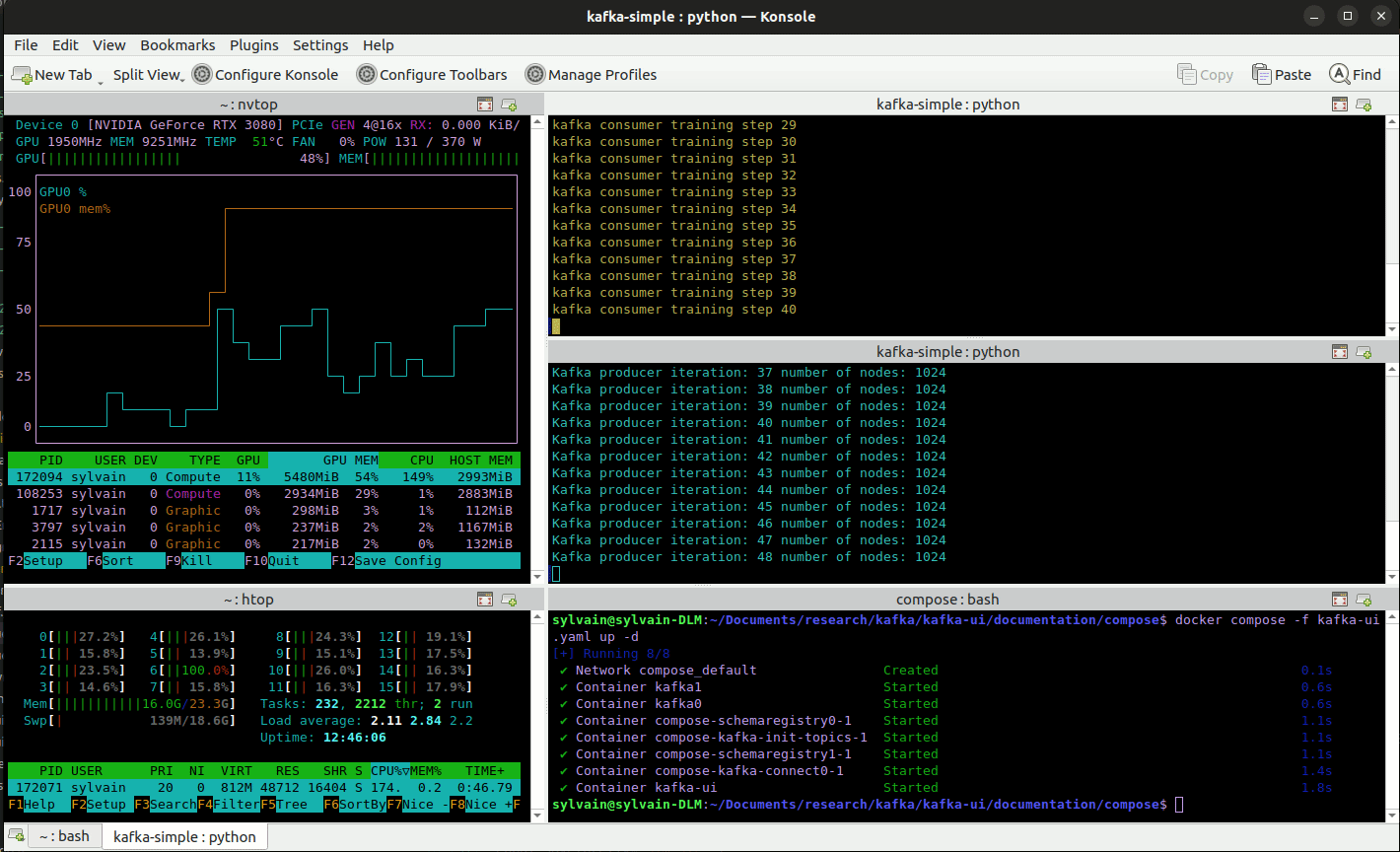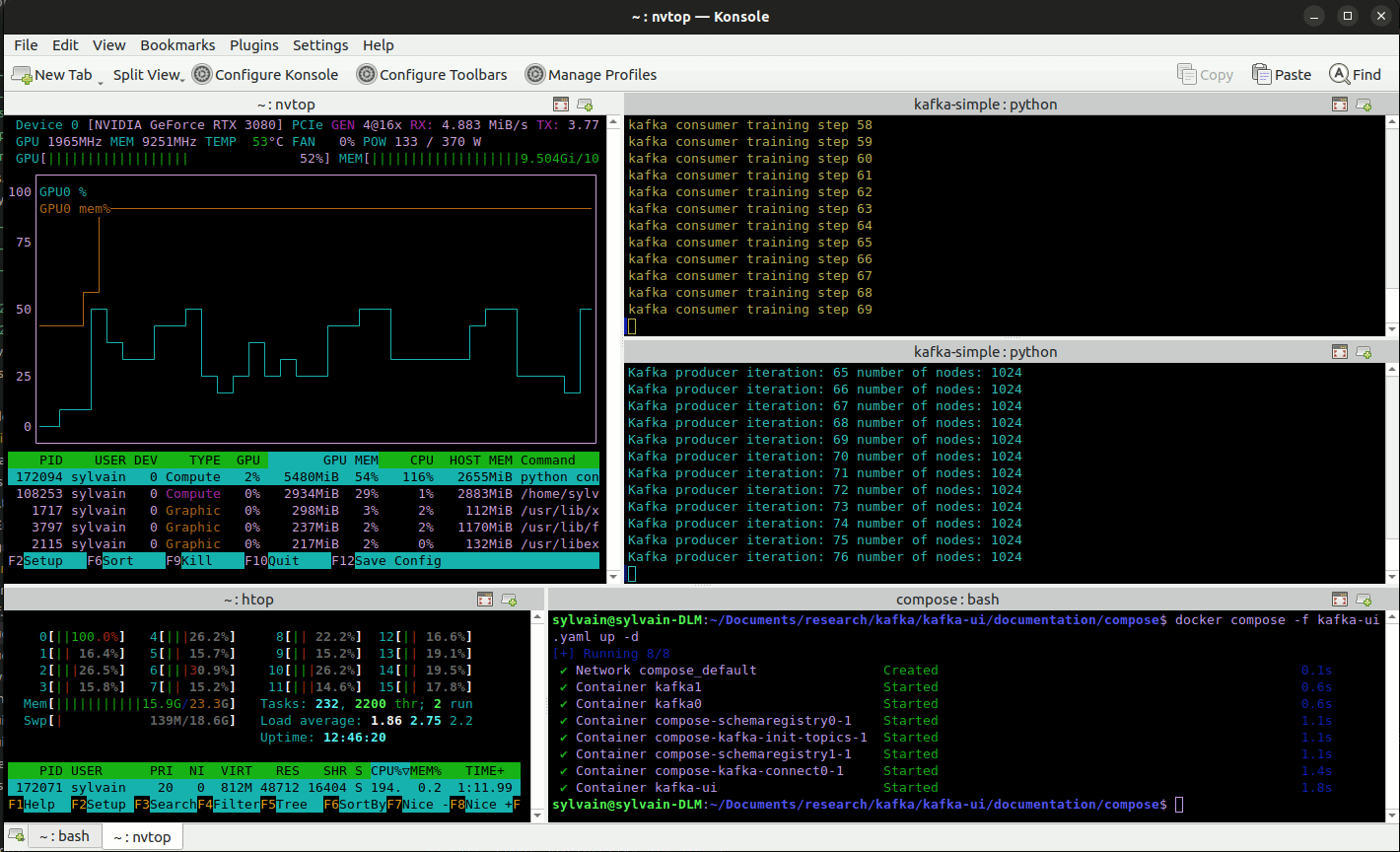
Source code
The source code of the pytorch EnPGF filter, the EnPGF lab, and the kafka streaming producer and consumer can be found in the github repository enpgf-lab. Running the code assumes that:
EnPGF pytorch
The pytorch EnPGF code should run directly providing that requirements, essentially pytorch, are satisfied. As in the example above, in a python console import EnPGF_Lab and load a data set using the command
from EnPGF_lab import *
dN,n,nstep = dN_load('dN_100000_128.csv.gzip')you then instanciate and train an EnPGF model
enpgf= EnPGF(n=n,nens=128,dN=dN,dt=0.1,device='cuda')
enpgf.train()
To execute the code on cpu in case nvidia GPU is not available (requires torch cpu only), set
device='cuda'
EnPGF Lab app
The app requires essentially dash components (see requirements) and can be run with
python app.pyit is then available at the address 0.0.0.0:8889 .
kafka online training
The online training framework requires a running apache streaming platform. Providing that the requirements are satisfied, the producer producer_spikes.py and consumer consumer_spikes.py can be excuted on a running kafka server after setting the bootstrap_servers address accordingly.
docker install
The docker install facilitates the installation of the packages by providing an isolated framework. From a terminal run the commands
git clone https://github.com/sdelahaies/enpgf_lab.git
cd enpgf_lab
docker compose up -dwhich install and set up and start the following containers:
docker exec -it enpgf-lab /bin/bashfrom which you can start a python or ipython console, or start a jupyter session via the command
jupyter notebook --ip 0.0.0.0 --no-browser --allow-rootavailable at 127.0.0.1:60000
References
[1] N. Santitissadeekorn, S. Delahaies, D.J.B. Lloyd, Identification of an influence network using ensemble-based filtering for Hawkes processes driven by count data, Physica D: Nonlinear Phenomena
[2] N. Santitissadeekorn, D. J. B. Lloyd, M. B. Short, and S. Delahaies, Approximate filtering of conditional intensity process for poisson count data: Application to urban crime, Computational Statistics & Data Analysis.