Cet article présente le projet fil rouge réalisé dans le cadre de la formation Data Engineer, DataScientest, Bootcamp jan-avr 2023:
Itinéraire de vacances: conception, implémentation, déploiement d’une application de recommandation d'itinéraire de vacances.
Soutenu en avril 2023 avec mes co-auteurs A. Bouttier, H. Elmi Ali, I. Noui.
Le concept : un utilisateur choisit une destination à visiter lors d'un prochain voyage ainsi que la durée du séjour et des centres d'intérêts. l’application lui propose un itinéraire détaillé, ie une séquence de points d'intérêts (POI) organisés dans le temps et l'espace, produit à partir d'un système de recommandation.
L'objectif : mettre en oeuvre le plus de compétences data Engineer au service d'un projet/service abouti.
Sommaire
Sources et structures de données
Architecture
Système de recommandation
Code source
Références
Sources et structure de données
DATAtourisme
DATAtourisme est une plateforme Open Data destinée à faciliter l'accès aux données publiques d'information touristique. Gratuite pour tous les utilisateurs, cette plateforme offre plus de 412 000 données normalisées de type événements et POI touristiques. Les données se limitent néanmoins aux territoires français.
Opentripmap
l'API opentripmap offre une base de données à l'échelle du globe accessible gratuitement. Riche, globale, et facile d'utilisation, cette API a été intégrée à l'application. Il est ainsi proposé à l'utilisateur de choisir sa source de données, DATAtourisme ou opentripmap.
Trip Advisor
Learder mondial incontestable pour tout ce qui a trait à l'information à caractère touristique sur internet, le site Trip advisor offre de multiples sources de données remarquables pour qui sait les recueillir. Plusieurs scripts de scraping ont été implémentés pour collecter des données sur les activités conseillées, les notes et avis d'utilisateurs. Attention toutefois à utiliser ces scripts avec prudence pour éviter le bannissement pur et simple de leurs serveurs.
Données annexes
Pour la mise en oeuvre de ce projet d'autres sources de données ont été nécessaires. En premier lieu l'application klarna.trips qui a inspiré d'une part la notion itinéraire et d'autre part la conception du planning journalier. Un script de scraping a été réalisé afin de requêter et de recuellir l'itinéraire proposé par l'application à partir d'un choix de destination, d'une période ainsi que de centres d'intérêts.
l'API de géocodage api-adresse.data.gouv.fr nous a permis de produire une barre de recherche de destination, point de départ pour la production de l'itinéraire.
Plus anecdotique, quoi que ..., l'intégration de l'API chatGPT d'OpenAI a été testée pour permettre à l'utilisateur muni d'une clé de se laisser guider par chatGPT.
Base de données
Le choix d'une base de données NoSQL MongoDB nous est apparu le plus approprié. Après téléchargement de l'intégralité du contenu de DATAtourisme un traitement a permis de regrouper l'ensemble des données utiles dans un fichier json facilement manipulable, passant d'un volume de données de 9GB à seulement 500MB facilitant la phase de développement. D'autre part, l'ensemble des données issues des requêtes API, du scraping des différentes sources externes, mais également les données utilisateurs, sont stockées sous forme de fichiers json en attente de traitement et d'insertion dans le base de données servant à l'entraînement du système de recommandation.
Architecture
Clean architecture
Il a été décidé de structurer le code selon les principes de la clean architecture en adoptant une structure en couches: les couches internes (entities, use cases) ne devant pas être conscientes des couches externes (dags, web). Ces principes garantissent l'indépendance de l'interface utilisateur, de la base de données et de service ou système externe, et permettent à l'application d'évoluer facilement.
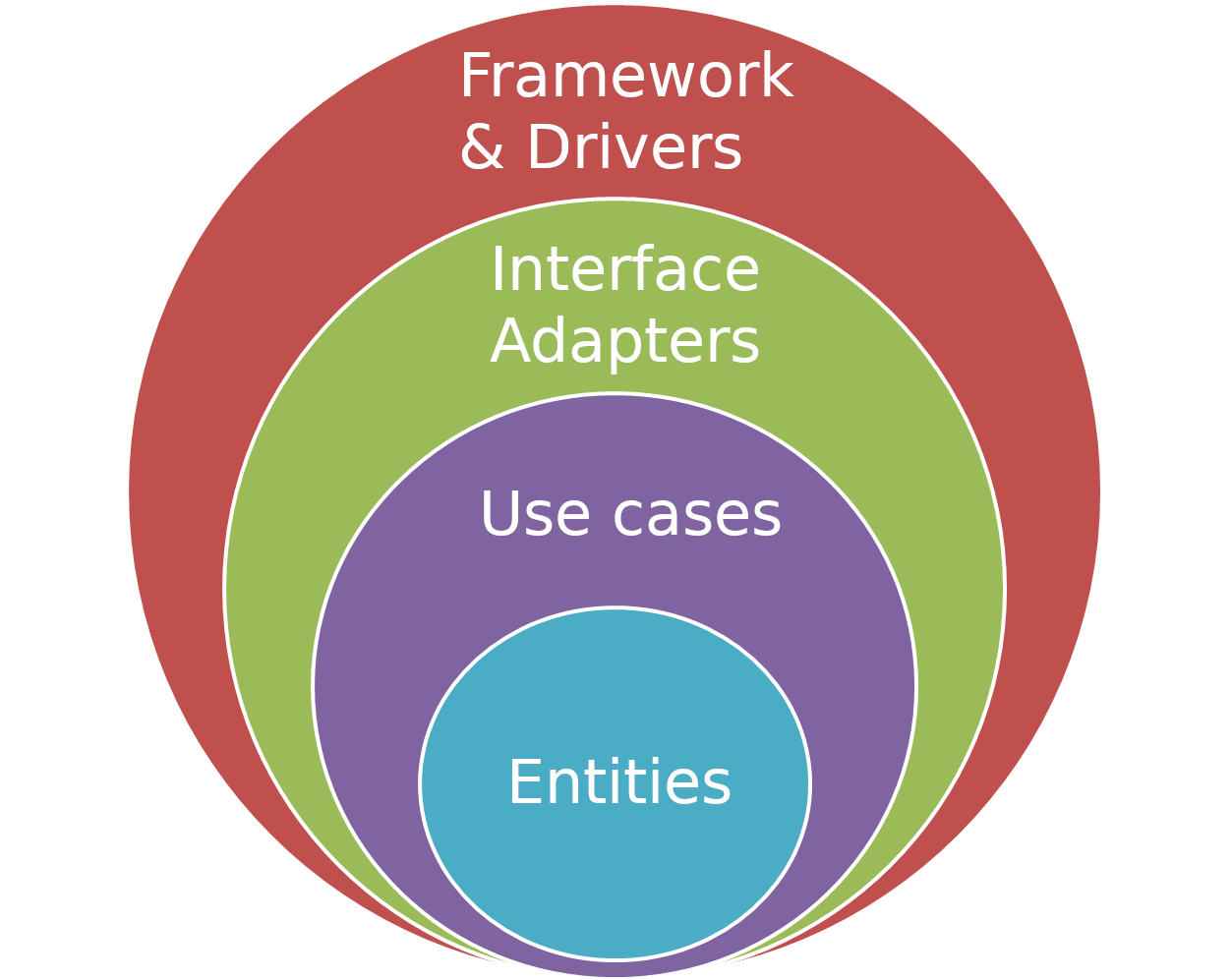
Docker
Docker est un outil open-source qui permet l'encapsulation d'une application et ses dépendances dans un conteneur isolé, garantissant et facilitant la portabilité. L'ensemble des fonctionnalités et services ont été conçus et assemblés sous forme d'une application multi-conteneurs avec Docker. Un fichier docker-compose.yml orchestre le fonctionnement des conteneurs, leurs dépendances, leurs connexions et les volumes partagés. Docker organise ainsi les services suivants:
docker compose up -d
...
airflow-webserver 8080->8080/tcp
airflow-scheduler 8793->8793/tcp
web 8181->80/tcp
mongo 27017->27017/tcp
mongo-express 8111->8081/tcp
clustering_api 8282->80/tcp
Système de recommandation
Proposer un itinéraire de vacances, défini pour rappel comme une séquence de POI organisés dans le temps et l'espace, consiste à suivre une recette pour concocter un assortiment d'activités supposé maximiser la satisfaction de l'utilisateur. Au coeur de cette recette, communément dénommé "algorithme" se trouve un système de recommandation. Domaine de recherche et d'application très actif depuis l'avènement du web et rendu incontournable avec le Big Data, les systèmes de recommandation tournent en continu derrière d'innombrables activités numériques.
Dans notre cas, à partir de la destination choisie par l'utilisateur et les types d'activités selectionnés, une requête de géolocation autour de la destination renvoie de quelques dizaines à plusieurs centaines de POIs. A raison de quelques activités réalisables par jour, il est important de pouvoir classer les POI sur une échelle de satisfaction associée à l'utilisateur. Un ensemble de règles vient ensuite affiner ce classement, l'organiser dans le temps et l'espace en respectant des contraintes prédéfinies, pour au final ne retourner que quelques POI sous forme de planning journalier.
Nous avons proposé une approche par filtrage collaboratif neuronal avec pytorch. Faute de temps et en l'absence de données utilisateurs exploitables, une version expérimentale du système de recommandation a été implémentée dans airflow. La production du planning journalier, utilisant un algorithme de clustering contraint sous scikit-learn, a quant à elle intégré l'application dans la fonctionnalité auto-planner.
# Neural Collaborative Filtering
import torch.nn as nn
import torch.nn.functional as F
class CFNet(nn.Module):
def __init__(self, n_users, n_items, emb_size=100, n_hidden=10):
super(CFNet, self).__init__()
self.user_emb = nn.Embedding(n_users, emb_size)
self.item_emb = nn.Embedding(n_items, emb_size)
self.lin1 = nn.Linear(emb_size*2, n_hidden)
self.lin2 = nn.Linear(n_hidden, 1)
self.drop1 = nn.Dropout(0.1)
def forward(self, u, v):
U = self.user_emb(u)
V = self.item_emb(v)
x = F.relu(torch.cat([U, V], dim=1))
x = self.drop1(x)
x = F.relu(self.lin1(x))
x = self.lin2(x)
return x
Code source
L'ensemble du projet est disponible sur github dans le dépôt travelplanner-full. Attention, l'ensemble du projet est gourmand en ressource et l'installation peut être relativement longue en fonction de votre configuration et de votre connexion internet.
Une version d'essai n'incluant ni airflow, ni pytorch, est déployée sur pythonanywhere au lien suivant app_travelplanner. Le code source est disponible dans le dépôt app_travelplanner.
Durant la phase de recherche, de nombreux prototypes se sont succédés utilisant streamlit au lieu du couple flask-dash. Un exemple est déployé sur la plateforme streamlit à cette adresse, le code source est disponible sur github dans le dépôt app-otm.
Références
Sources et structures de données, APIs :
Architecture et bibliothèques :
Système de recommandation :