The convergence of agentic frameworks and workflow automation has recently become a focal point in modern AI and data science. Tools like LangChain, flowiseAI and many others have revolutionized the way workflows integrate large language models and data processing. MLOPS pratices have also brought their share of orchestration and automation frameworks. Generative AI further enhances these frameworks by enabling more dynamic interactions, flexible reasoning, and adaptive decision-making. This trend underscores a growing need for streamlined solutions to handle complex computational workflows efficiently.
In this context, the demand for lightweight, adaptable frameworks capable of orchestrating various tools and techniques has skyrocketed. While robust platforms such as Apache Airflow exist, their complexity often makes them ill-suited for early-stage prototyping. Flowizer addresses this gap by providing a straightforward, extensible framework tailored to dynamic workflows with diverse data processing needs.
Why Flowizer Was the Right Choice for Prototyping
Flowizer emerged as the ideal solution for prototyping a carbon footprint analysis workflow. The project required the integration of advanced document processing, machine learning models, and emission factor retrieval techniques. Off-the-shelf solutions either lacked the flexibility or imposed steep learning curves, making them impractical for rapid development.
With its lightweight design and focus on configurable workflows, Flowizer allowed us to implement a fully functional prototype in a fraction of the time required by traditional platforms. Its dynamic architecture provided the freedom to incorporate a wide range of tools, from OCR and regex extraction to transformer-based classification models and LLMs, enabling seamless experimentation and iteration.
Flowizer Logic and Principles
At its core, Flowizer is a directed acyclic graph (DAG) workflow manager powered by a pub/sub system. Nodes in the DAG represent tasks, while edges dictate data flow between tasks. Each node listens for a trigger in its respective topic, ensuring that all prerequisites are met before execution. This approach minimizes resource contention and ensures efficient task orchestration.
The data exchange between nodes is facilitated through dictionaries, enabling flexible and dynamic data structures. Each node processes input data, performs its designated task, and emits output data to downstream nodes. Conditional branching further enhances Flowizer’s adaptability, allowing workflows to respond dynamically to varying inputs and execution conditions.
Key Features of Flowizer
- Dynamic workflow configuration via YAML files
- Support for conditional execution modes
- Graphical visualization of workflows
- Extensible node types for custom functionality
- Integration with RESTful APIs for external control
These features make Flowizer a versatile tool for prototyping workflows in diverse domains, from document analysis to machine learning pipelines. Its extensibility ensures that users can easily augment its capabilities with custom functions tailored to specific needs.
Workflow Configuration Example
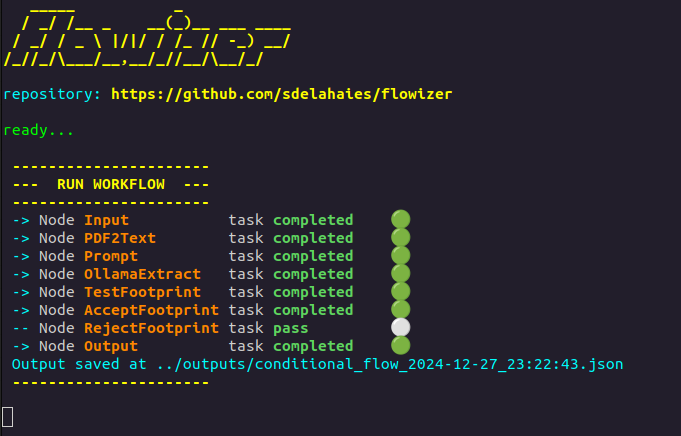
A Flowizer workflow is defined using a simple YAML configuration. Below is an example illustrating a document analysis pipeline:
---
name: conditional_flow
createdAt: 27-12-24 14:23:00
nodes:
- 1: Input,input_fn
- 2: PDF2Text,pdf2text_fn
- 3: Output,output_fn
- 4: Prompt,prompt_fn
- 5: OllamaExtract,ollama_fn_2
- 6: TestFootprint,testfootprint_fn
- 7: AcceptFootprint,acceptfootprint_fn
- 8: RejectFootprint,rejectfooprint_fn
flow:
- 1>>2
- 2,4>>5
- 5>>6
- 6>>7,8
- 2,5,7,8>>3
inputs:
- Input:
filename: "dell-xps-8960-pcf-datasheet.pdf"
params:
- OllamaExtract:
model: "llama3.2:3b"
system: "You are an expert in document analysis..."
- TestFootprint:
mode: conditional
- AcceptFootprint:
branch: A
- RejectFootprint:
branch: B
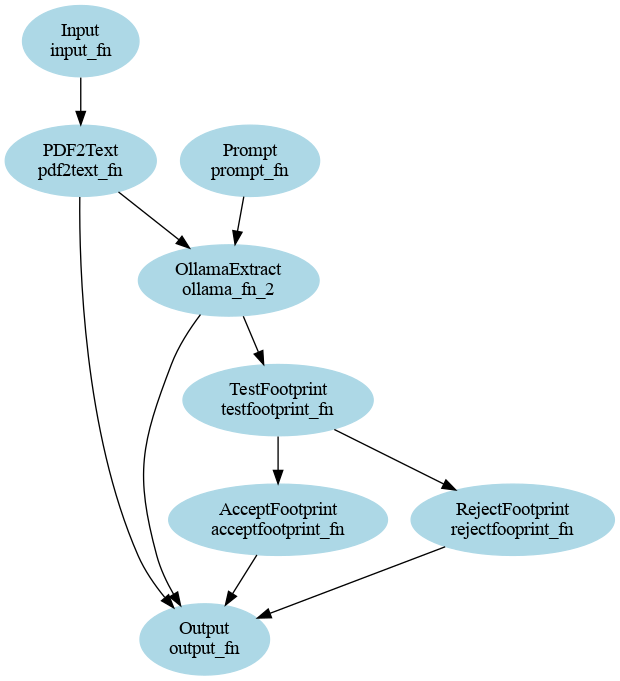
This YAML file defines nodes, their interconnections, and input parameters, providing a clear and concise way to manage complex workflows. The example above illustrates a conditional workflow for analyzing a PDF document, extracting relevant information, and operating a conditional choice based on the extracted data. Flowizer allows to visualize the workflow and its execution in a graphical manner using networkx as illustrated below.
Future Developments
While Flowizer has proven effective for prototyping, there are opportunities for further enhancement. First it has yet to integate agentic capabilities, that is to integrate reasoning and iterative planning to semi-autonomously solve complex, multi-step problems.
Future iterations could include tighter integration with popular frameworks like LangChain and vector databases, improved support for distributed execution, and a more user-friendly interface for workflow visualization and editing.
Additional features like automatic failure recovery, enhanced logging, and monitoring capabilities would also make Flowizer more suitable for production environments. Collaboration with the open-source community could accelerate these developments, ensuring Flowizer remains a competitive and innovative tool.