
During my postdoctoral research, I have had extensive experience with Truncated Singular Value Decomposition (TSVD) as a powerful yet simple tool for regularizing complex problems in the context of Data Assimilation. Over a decade ago, TSVD became an indispensable part of my workflow for addressing the ill-posed nature of these problems, where small perturbations in data could lead to large, unstable solutions. By selectively truncating the smaller singular values, TSVD not only reduced numerical noise but also highlighted the most influential components of the system, leading to more stable and interpretable results. The elegance and efficacy of TSVD left a lasting impression on me, and I am particularly excited to see its resurgence in modern machine learning contexts, such as its application in the LASER method for optimizing large language models.
In the rapidly evolving field of large language models (LLMs), balancing performance with computational efficiency remains a pivotal challenge. Recent work on Layer-Selective Rank Reduction (LASER) provides a promising method to enhance model accuracy and generalizability while simultaneously reducing memory consumption. LASER applies Truncated Singular Value Decomposition (TSVD) to the weight matrices of selected transformer layers, allowing for significant rank reductions without compromising model performance but also without the need for further fine-tuning, making it more efficient for large language models.
The authors of the original study demonstrate that LASER can achieve enhanced capabilities, especially on question answering tasks. Surprisingly, applying aggressive rank reduction (as low as 1% of the original rank) not only preserves accuracy but sometimes improves generalization across benchmarks. This is attributed to the method’s ability to discard less informative parameters, which may act as noise, and focus computational capacity on the most salient features of the input. Furthermore, LASER offers substantial memory gains, with some layers achieving compression ratios up to 100:1, making it a compelling approach for deploying LLMs in resource-constrained environments. A community article at HuggingFace provides further exploration with Mistral 7B
While LASER has proven its efficacy, further exploration of its interaction with other optimization techniques and extensions remains largely unexplored. This article will seek to address these gaps and extend the research on LASER through the following key questions:
Research Questions
-
How can LASER be composed with quantization techniques?
Quantization is a popular method for reducing the memory and computational costs of LLMs, applied by reducing the bit-width of parameters. Composing LASER with quantization could yield a highly efficient hybrid optimization strategy.- Method: We will investigate whether quantization can be applied directly to the reduced-rank matrices generated by LASER without significant loss of accuracy. Additionally, we will explore whether LASER’s rank-reduction process affects the efficacy of quantization.
- Hypothesis: Combining LASER with quantization will amplify memory savings, with minimal degradation in performance.
- Potential Outcomes: A hybrid LASER-quantization approach that achieves state-of-the-art compression ratios while maintaining or improving reasoning accuracy.
-
What is the effect of LoRA and QLoRA fine-tuning methods on TSVD? Is LASER more effective in this context?
LoRA (Low-Rank Adaptation) and QLoRA (Quantized LoRA) are efficient fine-tuning methods that have been shown to enhance task-specific performance in LLMs with very small datasets. However, their interaction with rank-reduction techniques like LASER remains unclear.- Method: We will analyze how fine-tuning with LoRA and QLoRA modifies the singular value distribution of weight matrices and assess whether LASER provides additional benefits when used before or after fine-tuning.
- Hypothesis: Fine-tuning with LoRA/QLoRA introduces additional rank structures that may complement LASER, potentially making LASER even more effective post-fine-tuning.
- Potential Outcomes: Insights into whether LASER and LoRA/QLoRA are additive, or whether one subsumes the benefits of the other.
-
Can we define a corpus-specific LASER?
Transformer models are typically trained on diverse corpora, but different tasks may demand different rank structures. A corpus-specific LASER could tailor rank reduction to maximize efficiency and performance for a given domain.- Method: We may try to develop adaptive rank-selection algorithms that analyze corpus-specific patterns (e.g., syntactic and semantic distributions) to identify optimal layers and ranks for reduction.
- Hypothesis: Task-specific corpora have unique characteristics that can be exploited to fine-tune rank-reduction strategies, resulting in better trade-offs between accuracy and memory savings.
- Potential Outcomes: The development of corpus-aware LASER techniques that outperform generic rank-reduction methods on specialized benchmarks. The question as to whether it is feasible to define a corpus-specific LASER, tailoring the method to specific datasets seems interesting. However, this would likely require continued pre-training on the targeted corpus, which may be time-consuming and could take a while to fully address.
A very fisrt look at truncated singular value decomposition
TSVD is a dimensionality reduction technique that approximates a matrix by retaining only its most significant components. The decomposition of a weight matrix W can be expressed as:
Where:
- \(U\) and \(V\) are unitary matrices.
- \(\Sigma\) is a diagonal matrix containing the singular values in descending order.
By retaining only the top \(k\) singular values and corresponding vectors, we obtain a rank-\(k\) approximation:
Here, \(k\) is much smaller than the rank of \(W\), significantly reducing the size of the representation.
The image below provides an example of rank-\(k\) approximation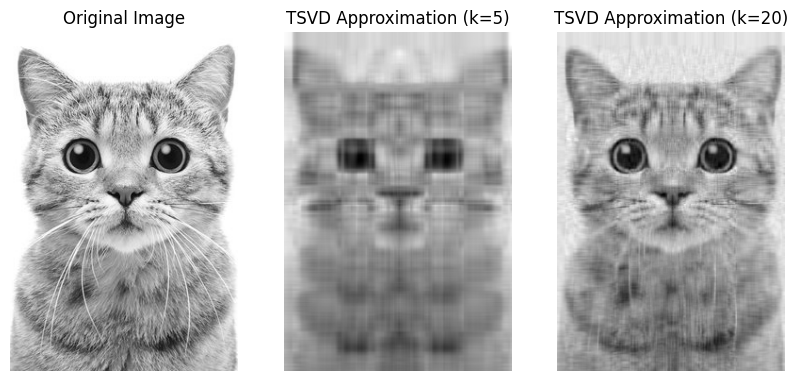
The condition number of a matrix \(W\), \(\kappa(W)\), is the ratio of its largest singular value to its smallest singular value:
SVD for Mistral-7B-Instruct-v0.2
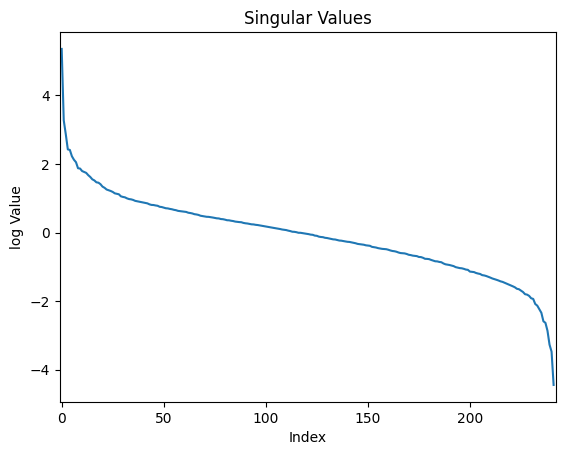
Before looking at any approximation, we take a look at the condition numbers and singular values distributions of each linear layer of Mistral-7B-Instruct-v0.2. The model is composed of 32 transformer layers, each containing several linear layers:
- self_attn: MistralAttention
- q_proj: Linear (in_features=4096, out_features=4096, bias=False)
- k_proj: Linear (in_features=4096, out_features=1024, bias=False)
- v_proj: Linear (in_features=4096, out_features=1024, bias=False)
- o_proj: Linear (in_features=4096, out_features=4096, bias=False)
- mlp: MistralMLP
- gate_proj: Linear (in_features=4096, out_features=14336, bias=False)
- up_proj: Linear (in_features=4096, out_features=14336, bias=False)
- down_proj: Linear (in_features=14336, out_features=4096, bias=False)
Building upon the foundational work on LASER and its application to the Mistral-7B model, as detailed in the insightful article on The LASER technique: Evaluating SVD compression , I have begun extending this research to the SmolLM2 model family. Initially, my focus will be on quantization techniques, with further exploration of Lora finetuning to follow. However, before sharing any conclusive findings, I will be conducting a comprehensive evaluation of the large language model (LLM) performance to ensure the results are both reliable and accurate. I look forward to sharing my insights and results as soon as I have robust data to report.
You can find the code and additional resources for this project on my GitHub repository: sdelahaies/laser-llm.
remark:Whereas using tsvd might always be beneficial in order to increase the performance of a model, depending on the dimension of the matrix and truncation rank, using \(U_r\), \(\Sigma_r\), and \(V_r\) separately can require more parameters than using the product \(U \Sigma V^T\). Indeed the individual matrices \(U\) and \(V\) are typically large and dense, while the product can be stored more compactly, especially when the rank \(r\) is much smaller than the dimensions of the original matrix. The widget below allows to play with the matrix dimensions and truncation rank.
LASER & Quantization
to appear ...LASER & Lora
to appear ...Links
- The Truth is in There: Improving Reasoning in Language Models with Layer-Selective Rank Reduction (LASER) by Pratyusha Sharma, Jordan T. Ash and Dipendra Misra
- The LASER technique: Evaluating SVD compression by Alberto Cetoli
- sdelahaies/laser-llm